I’ve written before about how one of the big changes in day-to-day medicinal chemistry over my career has been the rise of the huge catalogs of building blocks and intermediates. Here’s an article from ten years ago in C&E News that gives some good background. I think it’s really been a change for the better – as that first link shows, you can still make a lot of interesting (and unexplored) chemical matter using quite simple chemistry if you just have access to a large enough supply of potential coupling partners. And as I always take time to explain when I’m talking with grad student/postdoc audiences, discovery-stage medicinal chemistry is all about exploring chemical space as quickly and as reliably as you can, which means a lot of superficially boring classic reactions get run over and over. But that’s because our goal is not to do tricky and complex chemistry per se – we’ll do it if we have to, but our real goal is to make compounds that might turn into drugs. You have to make a lot of compounds to do that because you need to cover a lot of structure space, and they need to be novel (and therefore patentable), and you can’t take too long to do it, either.
There are some really nice compound collections out there to choose from, and of course a number of pharma companies have done some internal work to make novel intermediates for their own internal supply. But what else is out there? That’s the subject of this paper from Janssen (J&J), one of the organizations that’s clearly been thinking about that proprietary-building-block idea in detail. It refers to “Unorderable But Readily Synthesizable” building blocks, which is just the thing. They’re especially interested in developing techniques that could focus around some particular structures, the sort of thing you need to do a bit later on in a project after you’ve committed to a general scaffold but need to expand it.
The paper starts off with some simple bicylic amino alcohol compounds as a test case and it’s a solid one. These are perfectly solid med-chem building blocks – every experienced chemist I know would look at them and say “Sure, why not, seems fine” – but a large number of them are not commercially available. The authors assembled a large set of what is available, both from vendors and in-house, and then looked for simple one-step transformations (things like N-alkylation) to identify the easiest way to expand the available set. Even that first step is not quite as easy as it sounds. They concentrated on compounds that could be ordered immediately and were not synthesis-on-demand and that were available in at least 50mg quantities and cleaned up the list to account for salt forms, isotopic substitution, etc.
And here’s where the software comes in – they used features of the ASKCOS software suite to predict “synthesizability”, which is the sort of thing that just a few years ago people would have done (or tried to do) partially or completely manually. That program indeed has more than one tool specifically designed to look for one-step retrosyntheses and to sort them by likelihood of success. Here’s an example of another thing that I emphasize when I talk about where med-chem is going: doing this sort of thing “by hand” used to be part of the job description of a medicinal chemist, but it is now (and has been) slipping into the category of “grunt work to be done by a machine”. So adjust your career settings accordingly. But also note that this is a work in progress: the software’s “One-Step Retrosynthesis Fast Filter” did not do a particularly good job in this case, because it scored C-methylation as not all that different from N-methylation (whereas out here in the real world, the latter is almost always far easier). But the program’s scoring from the One-Step Retrosynthesis module itself did pick up on this, and turned out to be much more useful. So also note another point that I like to make: the software is improving a lot faster than we humans are.
They move on to a larger problem, with a project that needed some interesting hydroxy compounds to form ethers off of a proprietary scaffold. Going to the (basically exhaustive) GDB13 database of possible chemical structures, they extracted every single compound with 10 heavy atoms or fewer and a single OH group and then stripped out all the ones that had a conspicuously acidic or basic group, since the SAR would likely not tolerate either one. That cut the list down to a mere 223,163 alcohols, and only 1437 of them were available in-house or commercially (and had largely been exhausted already). The remaining 221,726 compounds were run through that ASKCOS scoring function, which gave 15,681 candidates for plausible one-step synthesis from known compounds. Further functional group filtration (getting rid of aldehydes and so on) stripped this down to 765 structures, and these were attached virtually to the substrate for calculation of cLogP, polar surface area, and the like. That narrowed the field to 338 alcohols, and applying the company’s proprietary chemoinformatics tools to that list sorted these by desirability. The top 12 were prioritized for synthesis.
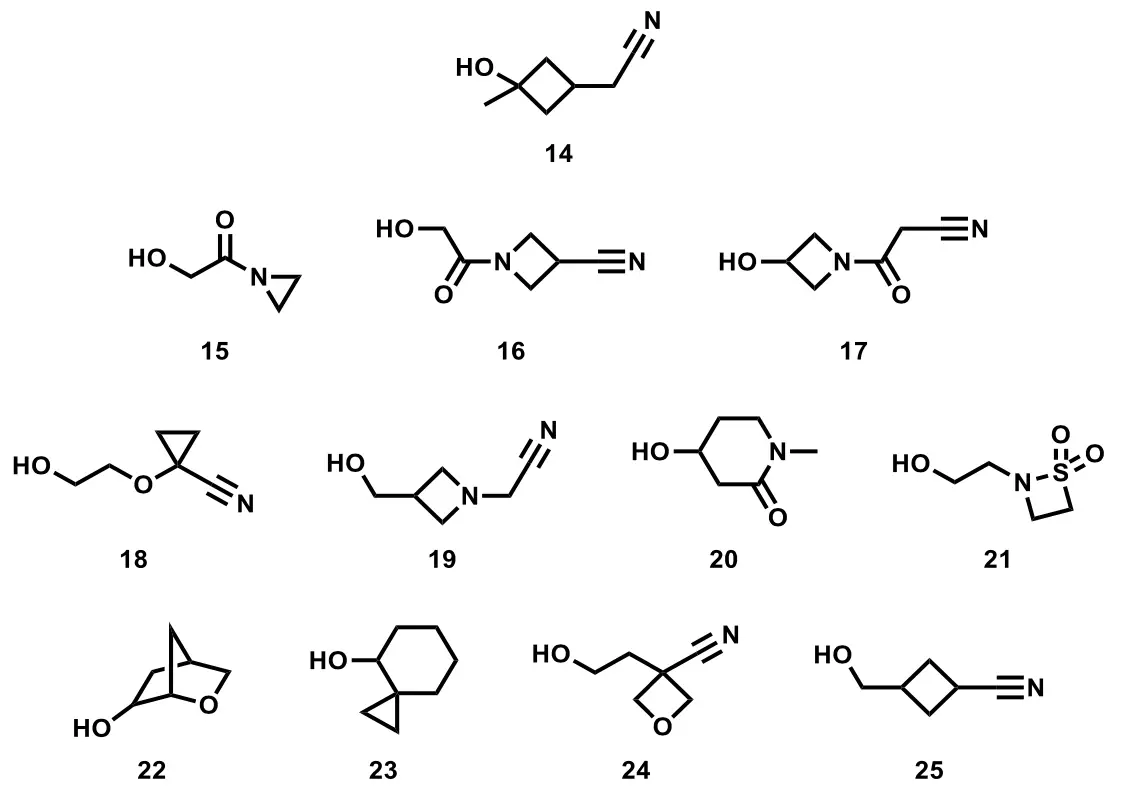
The list is shown at right. And as you can see if you read the paper, even synthesizing those 12 was not always straightforward. Some of the predicted reactions (reduction of commercially available esters, for example) worked roughly as advertised although none of the exact reaction conditions suggested by the retrosynthesis software worked exactly as written on the first try. Many of these just needed a slightly different reagent or altered conditions (solvent, temperature, etc.), but that tells you that the current state of the art is “suitable for a skilled organic chemist to realize” rather than “instant answers provided by machine”. That should be of some comfort to those who hear robotic footsteps coming up behind them. The epoxide opening reactions were trickier, and four of the compounds still could not be prepared at all. This was due in some cases to synthetic difficulties – the predicted reactions just flat didn’t work, and no alternative ideas worked either – and sometimes to things like this:
The attempted preparation of 23 is noteworthy: of the 12 alcohols we hoped to synthesize, this is the only example where the necessary starting material could not be easily ordered. Our curated set of reagents included ketone 49, and at the time of our order the vendor claimed this was available.39 Upon further inquiry it was found to be unavailable and also not available from any other vendor except for a willingness to attempt delivery within 3 months, a certainty and timeline not consistent with our concept of “readily available”.
Indeed. As Mark Twain said in one of his short stories, I only include this example because of its extreme unlikelihood – if I thought that any readers had ever experienced anything of the sort, I would certainly not have bothered to mention it (!) Overall, though, compounds 17, 21, 22, and 23 could not be synthesized easily, so those are left as an exercise for the readers, as the saying goes.
The authors estimate that there are at least 124,000 novel building blocks with ten heavy atoms or fewer that are potentially easy to synthesize, but as that exercise above shows, the key word is “potentially”. There are supply problems, and more than that, there are chemistry problems which as you can see the software is not yet completely equipped to deal with. Anyone making a frontal synthetic attack on those 124,000 compounds had better be prepared for a long campaign!
